



رگرسیون لجستیک چیست؟

رگرسیون لجستیک (Logistic Regression) یکی از الگوریتمهای مهم داده کاوی است که برای مسائل طبقهبندی استفاده میشود. در این الگوریتم، ما به دنبال یافتن رابطهای بین یک متغیر وابسته گسسته و متغیرهای مستقل هستیم، به طوری که بتوانیم دادهها را به دستههای مختلف تقسیم کنیم. یکی از ویژگیهای مهم رگرسیون لجستیک این است که خروجی آن احتمال تعلق یک داده به هر یک از دستههاست. قبل از وارد شدن به جزئیات و مبحث رگرسیون لجستیک، بهتر است کمی با دنیای یادگیری ماشین و طبقهبندی آشنایی پیدا کنیم.
مفهوم یادگیری ماشین
یادگیری ماشین به عنوان یکی از زیرمجموعههای هوش مصنوعی، امکانات بسیاری را برای ما فراهم میکند. این فناوری به کمک الگوریتمهای خاص، رایانهها را قادر میسازد تا از دادههای ورودی بدون نیاز به برنامهریزی صریح، یاد بگیرند و الگوها و روابط مختلفی را درون دادهها شناسایی کنند. از طرفی، این الگوریتمها میتوانند از این الگوها برای پیشبینی و تصمیمگیری درباره دادههای جدید استفاده کنند. با افزایش حجم دادهها و توسعه منابع محاسباتی، یادگیری ماشین به عنوان یک فناوری روبهرشد است.
الگوریتمهای یادگیری ماشین دارای انواع مختلفی هستند که هر کدام وظیفهها و استفادههای خاص خود را دارند. یادگیری تحت نظارت یکی از این انواع است که از دادههای برچسبدار برای آموزش مدل استفاده میکند. از سوی دیگر، یادگیری بدون نظارت الگوها و ارتباطات مخفی در دادههای بدون برچسب را شناسایی میکند.
یادگیری تقویتی با استفاده از پاداشها و تشویقها مدل را به یادگیری از تجربیاتش تشویق میکند. این الگوریتمها در حوزههای مختلفی مانند تشخیص تصویر، تشخیص گفتار و حتی تشخیص تقلب استفاده میشوند و در صنایعی مانند مراقبتهای بهداشتی، مالی و حملونقل نقش مهمی ایفا میکنند.
مطلب پیشنهادی: هوش تجاری چیست؟
مفهوم طبقهبندی یا Classification
در زمینه یادگیری ماشین، طبقهبندی یک روش مهم برای پیشبینی مقادیر خروجی بر اساس ویژگیهای ورودی است. در این روش، یک مدل بر اساس دادههای آموزشی با مقادیر خروجی شناخته شده آموزش داده میشود تا بتواند به درستی مقدار خروجی دادههای ورودی جدید را پیشبینی کند.
برای مثال، در حوزه تشخیص ایمیلهای اسپم، ویژگیهای مورد استفاده میتوانند شامل موضوع، آدرس فرستنده و محتوای ایمیل باشند. این ویژگیها با متغیر خروجی باینری که نشاندهنده ایمیل اسپم است یا خیر، مرتبط هستند. با استفاده از الگوریتمهای مختلف طبقهبندی میتوان به دقت بالاتری در پیشبینی خروجیهای جدید دست یافت و کارایی سیستم را افزایش داد.
در حوزه یادگیری ماشین، انتخاب مدل مناسب برای طبقهبندی دادهها امری بسیار حائز اهمیت است. انواع مختلفی از مدلهای طبقهبندی وجود دارد که هر کدام ویژگیها و مزایای خاص خود را دارند. برای مثال، رگرسیون لجستیک برای مسائل طبقهبندی دودویی مناسب است، درحالیکه درخت تصمیم و جنگلهای تصادفی برای مسائل چند دستهای موثر هستند. ماشین بردار پشتیبان نیز برای دادههای خطی و غیرخطی مناسب است، در حالی که شبکههای عصبی برای مسائل پیچیده و با دادههای بزرگ مؤثر هستند. طبقهبندی در زمینههای مختلفی مانند پردازش زبان طبیعی و تشخیص تصویر استفاده میشود و بهبود کارایی و دقت فرآیندها را افزایش میدهد. به طور کلی، طبقهبندی یک ابزار قدرتمند در یادگیری ماشین است که به بهبود تصمیمگیریها و اتوماسیون فرآیندها کمک میکند.
مطلب پیشنهادی: رگرسیون خطی چیست؟
مفهوم رگرسیون لجستیک
رگرسیون لجستیک یکی از الگوریتمهای مهم طبقهبندی است که در حوزه یادگیری ماشین مورد استفاده قرار میگیرد. این الگوریتم به خوبی برای پیشبینی و تفسیر دادهها مناسب است و به دلیل سادگی و کارایی آن، بسیار مورد توجه قرار گرفته است. یکی از موارد استفاده از رگرسیون لجستیک، تشخیص بیماریها و تومورها است.
با این الگوریتم، میتوان به دقت بالایی در تشخیص تومورهای بدخیم یا خوشخیم دست یافت. همچنین، در زمینه تجارت الکترونیک، میتوان از رگرسیون لجستیک برای تشخیص معاملات کلاهبرداری استفاده کرد. این الگوریتم با تحلیل دادهها و مشخصههای مختلف، توانایی پیشبینی صحیح را دارد و برای تصمیمگیریهای مهم و حیاتی، ابزاری قدرتمند و اثرگذار است.
همانطور که تا به اینجا متوجه شدیم، در رگرسیون لجستیک خروجی همواره به صورت ۰ یا ۱ است؛ به عبارت دیگر، یا بدبینی (۱) یا خوشبینی (۰). زمانی که تعداد کلاسهای خروجی ۲ باشد، به آن طبقهبندی دودویی گفته میشود؛ اما اگر تعداد کلاسها بیشتر باشد، آن را طبقهبندی چندگانه مینامیم.
این روش از توابع لجستیک برای تخمین احتمال پیشبینیها استفاده میکند و به ما این امکان را میدهد که دادهها را بهخوبی در دو کلاس مختلف تقسیم کنیم. از آنجا که ما به دنبال پیشبینی احتمال هستیم، تابع خروجی ما باید بین صفر و ۱ باشد تا بتوانیم بهدرستی دادهها را طبقهبندی کنیم؛ بنابراین، انتخاب تابع مناسب برای تخمین این احتمال بسیار حیاتی است و باید با دقت و دقت انجام شود تا به نتایج دقیق و قابل اعتمادی برسیم.
علت عدم استفاده از رگرسیون خطی
ما با استفاده از روش رگرسیون خطی میتوانیم مدلی بسازیم که بتواند تومورها را بر اساس اندازه آنها به دو دسته بدخیم و خوشخیم تقسیم کند. با تنظیم یک آستانه در محور x، میتوانیم تصمیم بگیریم که هر توموری که اندازه آن بیشتر از آستانه باشد، به دستة بدخیم تعلق داشته باشد و هر توموری که اندازه آن کمتر از آستانه باشد، به دسته خوشخیم تعلق داشته باشد.
در اینجا میتوان با تعیین یک حد نسبت به محور x، دادهها را به دو دسته تقسیم کرد؛ دسته اول شامل تمام دادههایی است که در سمت راست حد نسبت به محور x قرار دارند و به کلاس ۱ (مثبت) تعلق دارند و دسته دوم شامل تمام دادههایی است که در سمت چپ حد نسبت به محور x قرار دارند و به کلاس ۰ (منفی) تعلق دارند. این حد در اینجا برابر با ۰.۵ است.
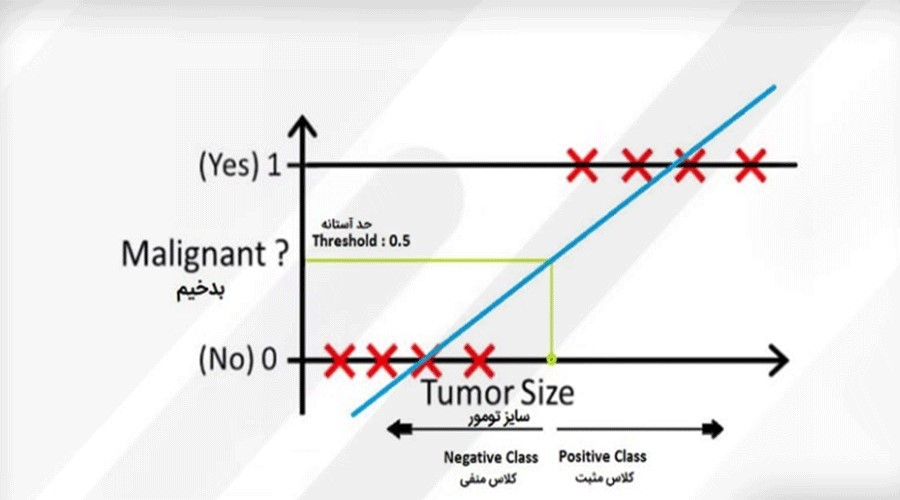
خب، تا به حال از رگرسیون خطی خوب استفاده کردهایم و به نظر میرسد که نیازی به رگرسیون لجستیک نداریم، اما واقعیت این است که هنوز به آن نیاز داریم. فرض کنید یک داده پرت به مجموعه دادههای ما اضافه شود؛ در این صورت، خطی که رگرسیون خطی به ما نشان میدهد، به شکل دیگری خواهد بود:
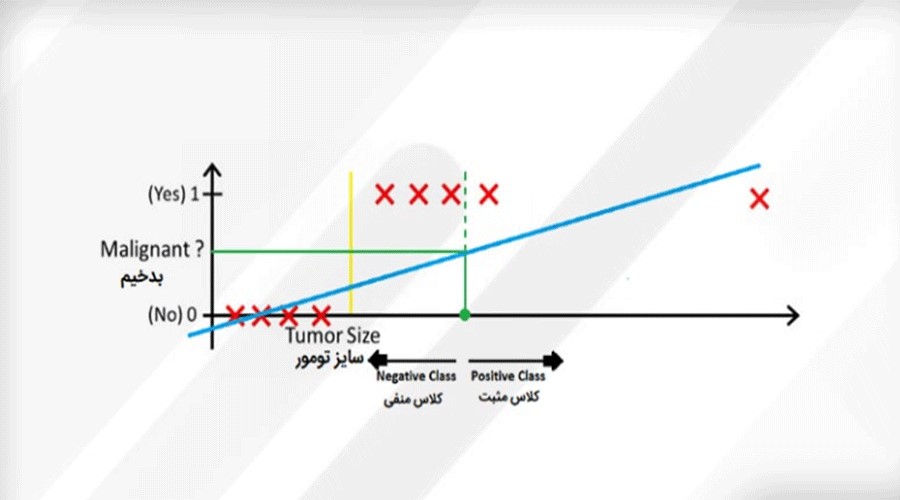
هنگام بازبینی مجدد بازه ۰.۵، متوجه میشویم که دادهها به درستی تقسیم نمیشوند؛ بسیاری از نمونههای مثبت به اشتباه در دسته نمونههای منفی قرار میگیرند. در واقع، باید تصریح کنیم که در اولین بار، رگرسیون خطی به طور اتفاقی دادهها را به درستی تقسیم کرده است؛ بنابراین، نیاز به استفاده از رگرسیون لجستیک داریم.
دلیل نیاز به رگرسیون لجستیک چیست؟
در رگرسیون خطی، معادلهٔ خطی برای تبیین ارتباط بین متغیرهای وابسته و مستقل استفاده میشود، اما در برخی موارد، این روش مناسب نیست و نیاز به یک مدل دیگری مانند رگرسیون لجستیک است. در رگرسیون لجستیک، ما با استفاده از تابع سیگموید یا لجستیک، احتمال تعلق داده به یکی از دو کلاس را بهدرستی مدلسازی میکنیم. این تابع، مقادیر خروجی را بیشتر از صفر و کمتر از یک میکند و به ما امکان میدهد تا احتمال تعلق داده به هر کلاس را بدست آوریم. به این ترتیب، با استفاده از رگرسیون لجستیک، میتوانیم دادهها را بهدرستی طبقهبندی کرده و مدلهای پیشبینی دقیقتری بسازیم.
در مدل رگرسیون خطی، معادلهٔ ما به این صورت بود: Z = β₀ + β₁X، اما در رگرسیون لجستیک، این معادله به شکل دیگری خواهد بود. به عبارت دیگر، معادلهٔ خطی کلاسیک به شکل سیگموید تبدیل میشود که در رگرسیون خطی اینگونه نبود.
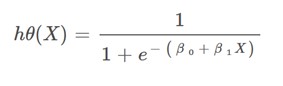
قبل از بررسی روش بهینهسازی پارامترها، بهتر است در مورد مرز تصمیمگیری نیز صحبت کنیم.
مرز تصمیمگیری
زمانی که ورودیها را از یک تابع پیشبینی عبور داده و احتمال خروجی را بین صفر تا یک مشاهده میکنیم، انتظار داریم طبقهبندیکنندهٔ ما بر اساس احتمال، یک مجموعه از کلاسها را به ما ارائه دهد. به عنوان مثال، اگر دو کلاس گربه و سگ (کلاس ۱ برای سگ و کلاس صفر برای گربه) داشته باشیم، یک آستانه را در نظر میگیریم که هر دادهای بالای آن به کلاس یک و هر دادهای زیر آن به کلاس صفر تعلق مییابد.
با انتخاب آستانه ۰.۵، اگر تابع پیشبینی مقدار ۰.۷ را برگرداند، داده را به عنوان سگ طبقهبندی میکنیم، اما اگر پیشبینی ۰.۲ باشد، داده را به عنوان گربه طبقهبندی میکنیم. مرز تصمیمگیری به ما کمک میکند دو کلاس را از هم تمیز دهیم و این مرز به وضوح توسط تابع لجستیک مشخص میشود.
تابع هزینه
در رگرسیون لجستیک همانند رگرسیون خطی، ابتدا یک تابع با پارامترهای تصادفی داریم که با استفاده از تابع هزینه بهینه میشود تا بهترین نتیجه را در خروجی ارائه دهد؛ به طور دقیقتر، دادهها به درستی دستهبندی شوند. تابع هزینه میزان خطا را بین کلاسی که پیشبینی شده است و کلاسی که واقعاً داده به آن تعلق دارد، مشخص میکند.
وقتی در نمودار y = 1 پیشبینی ما برای y = 0 باشد، به این معنی است که مدل ما داده را به طور اشتباه طبقهبندی کرده است و هزینه به سمت بینهایت افزایش مییابد. همچنین، در نمودار y = 0، اگر پیشبینی مدل ما برای y = 1 باشد، هزینه نیز به سمت بینهایت افزایش مییابد.

گرادیان نزولی
در حال حاضر، ما با یک سؤال مواجه هستیم: چگونه میتوانیم این خطا یا هزینهای را که با تابع هزینه به دست آوردیم را کاهش دهیم تا خروجیمان بهینه شود؟ جواب این سؤال در الگوریتم گرادیان نزولی است که با مشتق زنجیرهای هر پارامتر (به عنوان مثال β₀ و β₁) نسبت به خطا، مقدار مشتق را از مقدار پارامتر قبلی کم کرده و آن را بهروز میکند. این فرایند چندین بار تکرار میشود تا پارامترهای ما بهینه شوند و خروجی مدل بهبود یابد.
در واقع، گرادیان نزولی مانند این است که خودمان را در بالای کوهی تصور میکنیم، در حالی که چشمانمان بسته است و هدفمان رسیدن به پایین کوه است. برای دستیابی به این هدف، باید سراشیبی را قدم به قدم به سمت پایین برویم که همانند محاسبه گرادیان نزولی است و هر بار با بهروزرسانی پارامترها، یک قدم به سمت بهبود میبریم.
مطلب پیشنهادی: رمزنگاری چیست؟
جمعبندی
رگرسیون لجستیک یکی از مهمترین الگوریتمهای یادگیری ماشین است که برای مسائل طبقهبندی استفاده میشود. این الگوریتم در واقع یک مدل احتمالاتی است که برای پیشبینی احتمال تعلق یک داده به یک یا چند کلاس مشخص استفاده میشود. در این الگوریتم، از یک تابع لجستیک برای تبدیل مقادیر خطی به احتمالات استفاده میشود. این الگوریتم میتواند برای مسائل مختلف مانند پیشبینی احتمال ابتلا به یک بیماری، تشخیص هویت از تصاویر یا تشخیص اسپم ایمیلها استفاده شود. از آنجایی که رگرسیون لجستیک یک الگوریتم پرکاربرد و کارآمد است، هر کسی که به دنبال یادگیری ماشین و دادههای بزرگ است، باید با این الگوریتم آشنا باشد و بتواند از آن به درستی استفاده کند.

.svg)
